
and Why It Matters to all of Us
There was a lot of noise around the launch of OpenAI’s GPT-5 this month and a few voices noted the shift from chasing benchmarks to everyday value for individual and corporate users. Maybe a good
moment to take a look at those rankings.
On the highest level we measure AI models against our own capabilities, trying to figure out when and where they surpass our own brains. Which might be pointless, considering the heuristic
perspective. In our own limitations, how would we recognize that something is beyond it?
Since computers, software and the first sorts of artificial minds were invented, people think hard about ways to test their abilities. Alan Turing’s test in the 50ies was actually only measuring the ability to CONVINCE - people had to judge if they were talking to a machine or a human. Which isn’t the point today, when
we see people getting into delusional rabbit holes
with ChatGPT and studies showing the persuasiveness of LLMs.
In the last couple of years, with generative AI models being publicly available, advancing in their capabilities, and diversifying more or less daily, there is a growing need to compare and
classify the models and tools.
Several LLM benchmarks have been created by research groups, universities, tech companies, and open-source communities. They vary a lot in terms of methodology and have become more sophisticated
and specialized over the past years to compare the candidates.
common Benchmarks
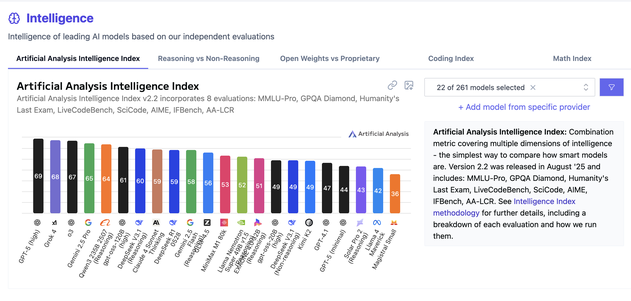
Here’s an overview of the most widely recognized LLM benchmarks and leaderboards:
- ArtificialAnalysis AI Leaderboard compares over 100 AI models on metrics such as intelligence, performance, speed, and cost. Offers holistic cross-model insights and runs several benches and leaderboards on specific models (text-to-video, text-to-speech etc.) and measures various aspects. Read about their methodology and definitions (helpful glossary!), and if you are interested in the frontier model development over time or per AI lab look into https://artificialanalysis.ai/trends
- LMarena by Berkeley researchers - This leaderboard uses a crowdsourced, user-centric approach where models compete against each other in a blind test. Users chat with two anonymous models and vote for the one they prefer. The ranking is then determined using the Elo rating system, similar to chess rankings. This method is particularly good at measuring conversational ability and helpfulness. Read about the idea behind: https://lmarena.ai/how-it-works
- Vellum AI LLM Leaderboard provides a comprehensive, real-time ranking of LLMs. It features a variety of benchmarks, including those for reasoning (GRIND), coding (SWE Bench), and tool use (BFCL). The platform provides both provider-reported data and independent evaluations (”evals”) to offer a dynamic view of model performance. They also have a specific open source model leaderboard and the blog offers a lot of tool insights.
- LiveBench is a detailed, real-time leaderboard that evaluates LLMs across various metrics, including reasoning, coding, data analysis, and language tasks. They limit potential contamination by releasing new questions regularly; right now, it has about 21 tasks in 7 categories. It offers a granular look at how different models perform in specific domains, which is useful for professionals and researchers.
- MMLU(Massive Multitask Language Understanding) is a widely cited benchmark that evaluates an LLM's multitask accuracy in zero/few-shot settings across 57 subjects, including humanities, social sciences, law, and STEM. It consists of multiple-choice questions designed to test a model's ability to generalize and apply broad knowledge. MMLU is a key metric in many overall leaderboards. It is hosted on GitHub, so rather for experts (although I always recommend familiarizing with GitHub to better understand how the global tech community works).
- HellaSwag is a challenge dataset, based on scientific research for commonsense reasoning, and it is designed to be difficult for models to cheat by simply memorizing patterns. The tasks require a nuanced understanding of real-world contexts and logical inferences to complete a given passage.
- Or you trust real people doing real stuff (well, I presume devs to be represented overproportionally) and see token distribution on the openrouter leaderboard: https://openrouter.ai/rankings
- A special, often-referred-to benchmark is ARC-AGI, founded by Francois Chollet, Mike Knoop, and led by Greg Kamradt, being on a mission to track the steps to AGI as smart and unbiased as possible. It’s interesting how the leaderboard and why they think the consensus definition of AGI as "a system that can automate the majority of economically valuable work" is not suitable to truly measure systems’ intelligence. Key point is to test the capabilities in novel, unseen environments. The team currently develops ARC-AGI-3, designed to measure AI system generalization and intelligence through skill-acquisition efficiency.
- TheLetta Leaderboard measures LLM efficiency in agentic memory tasks and persistence, with depth in long-range task planning.
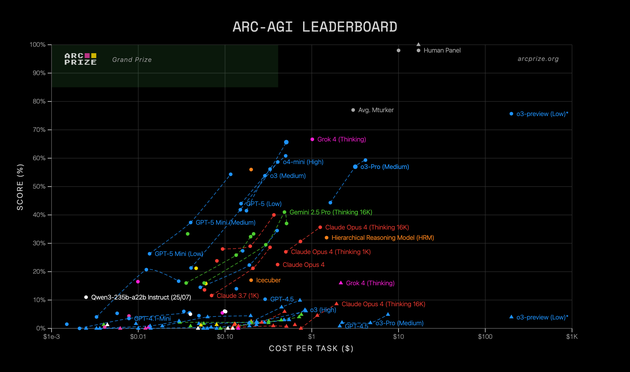
the specialized ones
- TrustLLM is a benchmark that focuses on the trustworthiness of LLMs. It measures various aspects of a model's behavior, including safety, sycophancy, privacy, and resistance to adversarial attacks. The benchmark is designed to help researchers and developers build more reliable and ethical AI systems.
- FairMT-Bench is a benchmark framework focused on measuring fairness in multi-turn dialogues for conversational LLMs. It evaluates models across three stages: context understanding, interaction fairness, and fairness trade-offs. The benchmark is designed to uncover and address biases that can accumulate over the course of a conversation, which is a critical issue for real-world applications.
- The latest one: https://www.prophetarena.co/ (by University of Chicago) The models get fed news articles and market data, then place probabilistic bets. When events resolve, it’s possible to see which model actually understood the world versus who was just pattern-matching.
- There are specific leaderboards for coders, e.g.
- Aider LLM Leaderboards Aider's leaderboards are specialized for evaluating an LLM's ability to act as a code-editing assistant. They use benchmarks like the "polyglot" test suite, which includes challenging coding exercises across multiple programming languages. Aider focuses on a model's capacity to follow instructions and successfully edit existing code without human intervention, which is a practical and real-world-oriented metric.
- HumanEval, developed by a group of OpenAI researchers, is a benchmark for evaluating the code generation capabilities of LLMs. It consists of a set of Python programming problems, and models are judged on their ability to produce functionally correct and executable code that passes unit tests.
- SWE-Bench is the most relevant benchmark for evaluating agents on real-world software engineering tasks. It requires agents to resolve GitHub issues by generating and applying code changes. It tests not just coding ability but also agentic reasoning, planning, and tool use to navigate a complex environment.
- The WebArena team developed an agent framework for web action and the related Agent Company tests LLM agents on tasks that require interacting with real-world websites. It measures an agent's capability to do things like online shopping, navigate user interfaces, extract information, and complete goals in a dynamic environment.
- The Galileo AI Agent Leaderboard is hosted on Hugging Face, and provides a detailed ranking of agents based on metrics like Average Action Completion (AC), Tool Selection Quality (TSQ), and cost-effectiveness. It focuses on the practical, business-oriented aspects of agent performance, making it useful for developers and companies building agentic systems.
- The new AstaBench leaderboardis run by the non-profit institute AI2 andtests AI agents on real scientific research tasks like literature review, data analysis, and code execution.
What for?
As we look at the growing list of AI benchmarks it becomes pretty clear that the way we measure AI says as much about us as it does about the models. This brings us to the bigger question of
purpose: Are we trying to replicate or surpass human capabilities, or do we need to reevaluate the definition of intelligence entirely?
Benchmarks are powerful because they give us a sense of direction. In corporate settings, benchmarks help to make decisions and they shape which models show up in our tools, apps, and workplaces.
For the AI labs, they determine how much money they can get from investors.
But let’s ask ourselves: what kinds of benchmarks are still missing if we truly want AI to serve human goals? Where are the tests for value consistency, for social cohesion, for long-term
collective benefit?
AI literacy means being able to ask these questions - knowing about the range of models and their scores on the leaderboards, but also how those scores relate to real human needs. As our world is
increasingly shaped by automated systems, we owe it to ourselves to stay informed, stay reflective, and above all, stay naturally human.
What would we benchmark if the goal was not just smarter models, but a better future?
Follow me on Substack to join the conversation.
Write a comment